Nov 12, 2024
Ultravox: An open-weight alternative to GPT-4o Realtime
Today we’re thrilled to introducing Ultravox v0.4.1, a family of multi-modal, open-source models trained specifically for enabling real-time conversations with AI. We’re also releasing Ultravox Realtime, a managed service that builds on top of our open-source foundations to integrate real time AI voice conversations into applications.
Unlike most voice AI systems, Ultravox does not rely on a separate automatic speech recognition (ASR) stage. Rather, the model consumes speech directly in the form of embeddings. This is the first step in enabling truly natural, fluent conversations with AI. We encourage you to try our demo to see Ultravox in action.
Ultravox shows speech understanding capabilities that are approaching proprietary solutions like OpenAI’s GPT-4o and are markedly better than other open source options. Our primary method of evaluation is speech translation, measured by BLEU, as a proxy or general instruction-following capability (higher numbers are better)¹:
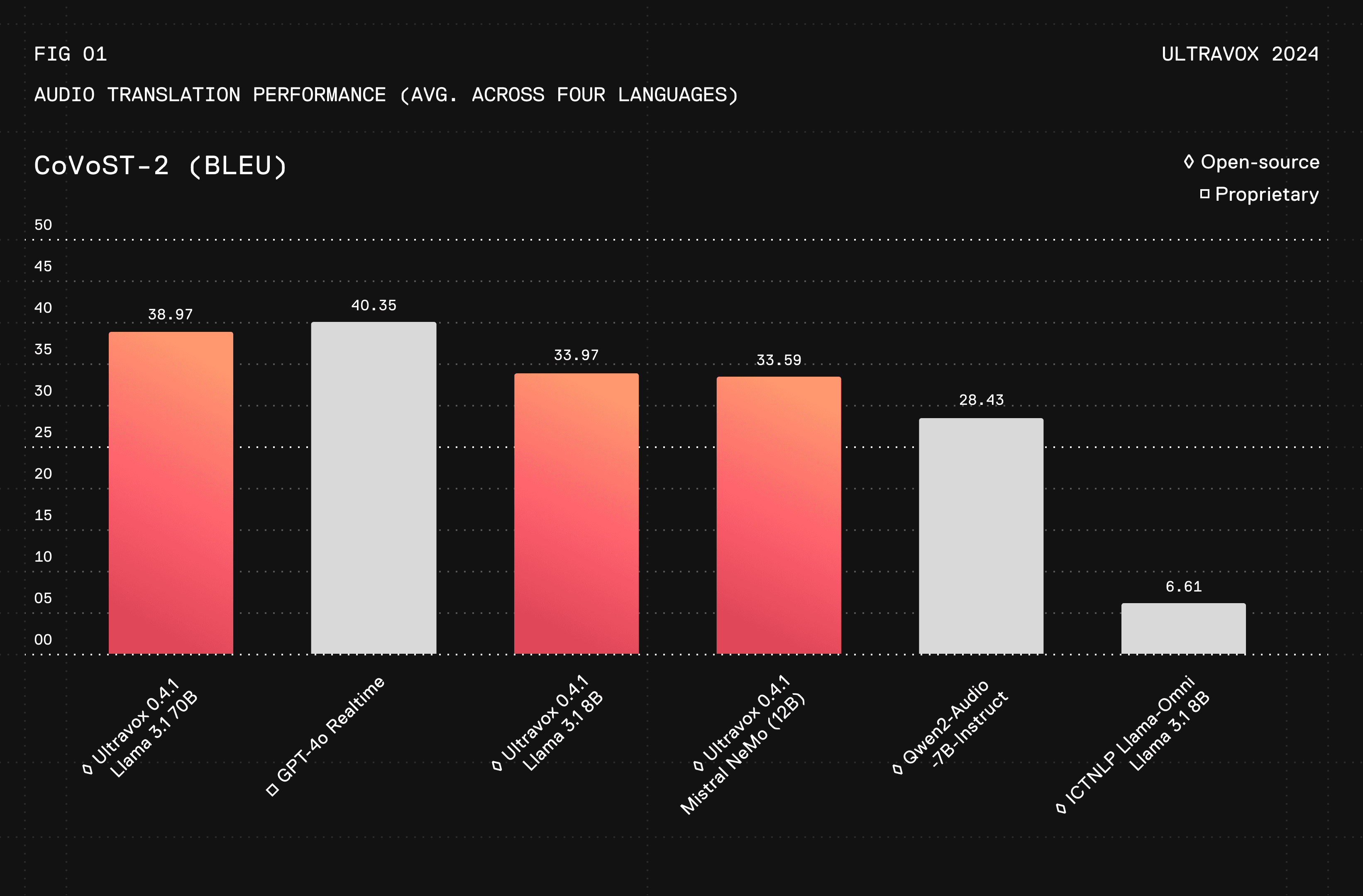
Ultravox can be trained against any open-weight model. We’ve trained versions of Ultravox on Llama 3.1 8B & 70B and Mistral NeMo. Model training code is available on Github and the weights are on HuggingFace. For training your own version of Ultravox on another model or different data sets, see this section of the README.
Ultravox Realtime
In addition to the core model work, we’re also opening access to Ultravox Realtime, a set of managed APIs that make building on top of Ultravox fast and easy. When compared with OpenAI Realtime, Ultravox sees comparable latency performance.
Ultravox Realtime has built in support for voices, tool calling, telephony, and many of the other critical pieces necessary for building powerful Voice agents. SDKs are available for most major platforms and you can get started by signing up today at https://app.ultravox.ai. We’re including 30 minutes of free time to get started, after which it's only $.05/min. This makes it considerably cheaper than alternative offerings.
Ultravox Realtime builds on top of all the work that we’ve already made open source through the Ultravox repo itself and the vLLM project. Additionally, because we’re built on top of open-weight models, Ultravox Realtime can be easily customized and deployed directly onto your own infrastructure.
How Ultravox Works
The majority of AI voice implementations today rely on pipelining together speech recognition (ASR), model inference, and text to speech (TTS). While this system works for basic use cases, it fails to scale to more complex situations (e.g., background speakers, noisy environments, group conversations, etc) or where the dialogue is less formulaic (i.e., conversations without very clear turn taking). Additionally, the pipeline system introduces latency that makes natural-feeling conversation nearly impossible.
These are all problems that we’ve experienced first-hand. Our experiments with real-time AI started over a year and a half ago when we built Fixie Voice, our first attempt at enabling real-time conversation with LLMs. Despite being considerably better than classic voice-based assistants like Siri or Alexa, the conversations still felt “fake.” It was clear that the model didn’t really understand dialogue, and it could easily become confused by very common scenarios in the real world such as background speakers or natural pauses in the thought process.
The reason for this is relatively simple: pipeline systems suffer from high information loss. The ASR process strips away all context, leaving only text behind. Communication is not just about the words that we say, but how we say them and in what context. This includes emotion, intonation, tenor, and other paralinguistic signals.
Ultravox is designed to ultimately address the shortcomings of the pipeline system by training a unified model with comprehensive speech and language understanding. By giving the model more context, we can better leverage the full power of the LLM to understand what the user is trying to say.
For now, Ultravox continues to output text, but future versions of the model will emit speech directly. We’ve chosen to focus on the speech understanding problem first, as we think it’s the biggest barrier to natural-feeling interactions.
To be clear, even though Ultravox has competitive speech understanding capabilities, there is still a lot of work to be done. We outline a roadmap below that shares our intended path towards achieving truly natural communication with AI.
Roadmap to Human-level Voice AI
Our belief is simple: We think useful, productive, and accessible AGI will require models that can operate in the fast-paced, ambiguous world of natural human communication. Whether it’s support agents on the phone, AI employees joining critical meetings, or humanoid robots in the home – AI will never reach its full potential until it can cross the chasm into the “real” world.
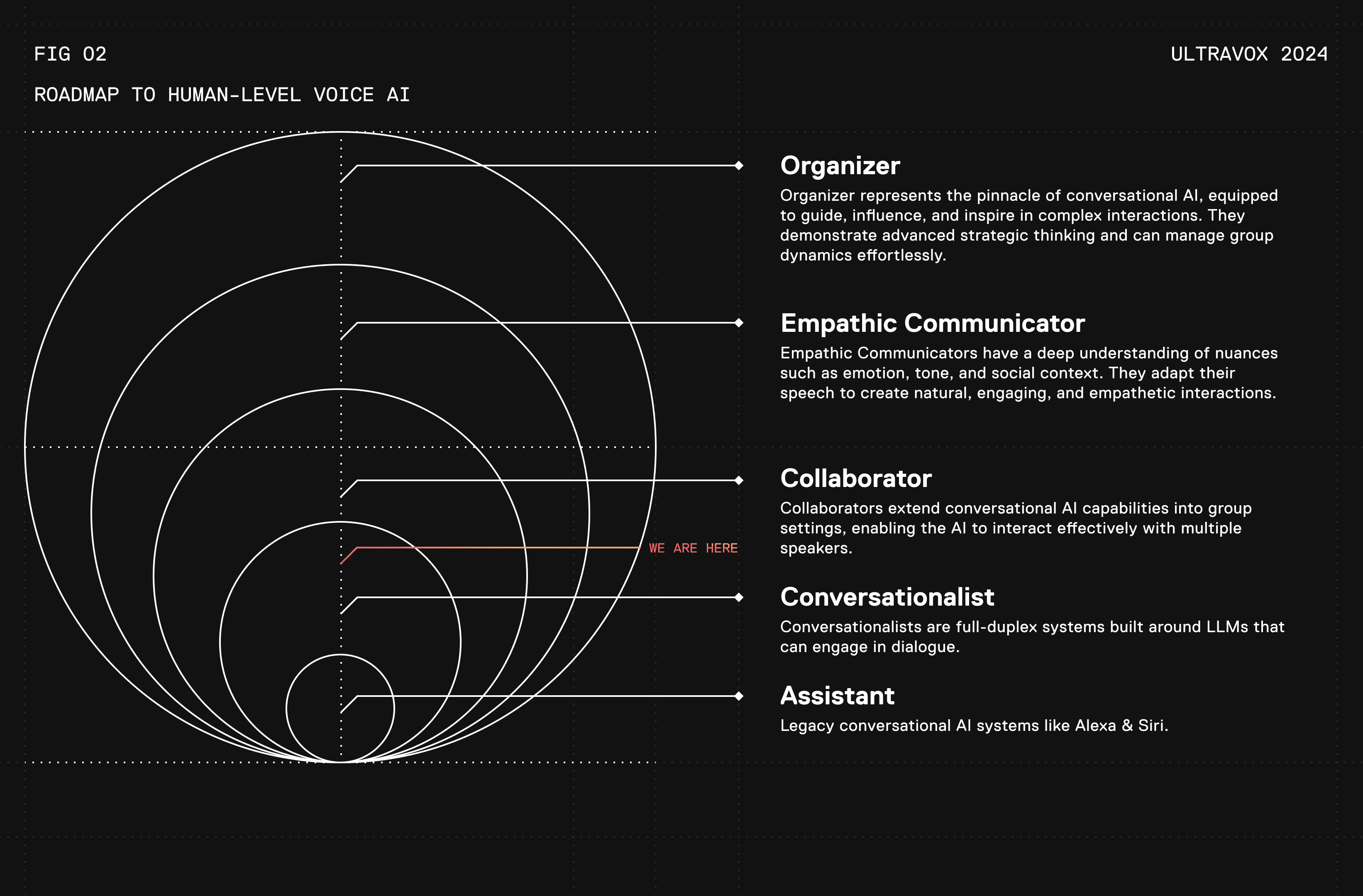
We’re sharing our internal framework for achieving what we see as human-level voice AI.
Level 1: Assistant
Assistants are basic systems that alternate between listening and speaking modes. They are designed to provide simple information and execute basic tasks, similar to legacy voice assistants like Siri, Alexa, and Google Assistant. They are unable to carry context between turns (i.e, they are not conversational).
Level 2: Conversationalist
Conversationalists are full-duplex systems built around Large Language Models (LLMs) with the ability to engage in dialogue. Naive Conversationalists rely on separate components like Voice Activity Detection (VAD), Automatic Speech Recognition (ASR), and Text-to-Speech (TTS), which can limit the smoothness and natural feel of conversations due to component inefficiencies. In contrast, Natural Conversationalists use an integrated, end-to-end approach that enables them to understand and generate speech directly, offering seamless, expressive, and engaging one-on-one interactions.
Note: Ultravox has surpassed Naive Conversationalist, but is not yet what we would define as an “Natural” conversationalist. We think this is true for GPT-4o Realtime as well.
Level 3: Collaborator
Collaborators extend conversational AI capabilities into group settings, enabling the AI to interact effectively with multiple speakers. These systems can manage social dynamics and add significant value to professional environments and real-life applications. Collaborators are active and valuable members of a team, contributing effectively to collaborative tasks and facilitating productive teamwork.
Level 4: Empathic Communicator
Empathic Communicators have a deep understanding of nuances such as emotion, tone, and social context. They adapt their speech to create natural, engaging, and empathetic interactions, making them ideal for roles that require high emotional intelligence and the ability to form meaningful connections in both personal and professional settings.
Level 5: Organizer
Organizer represents the pinnacle of conversational AI, equipped to guide, influence, and inspire in complex interactions. They demonstrate advanced strategic thinking, manage group dynamics effortlessly, and deliver communication with charisma and authority.
Join Us
If you’re excited by what we’re trying to build, come join us! We’re actively hiring for engineers and research scientists. More here.
—
¹ Evaluation was performed using the following prompt: f"Please translate the text to {{language}}. Your response should only include the {{language}} translation, without any additional words:\n\n{AUDIO_PLACEHOLDER}"